前言
java 集合类 HashMap 为非线程安全,在高并发场景下如果错误使用HashMap会导致代码陷入死循环,服务器load飙升;jdk为HashMap提供了线程安全版本 ConcurrentHashMap,支持高并发场景下使用,并提供了额外的并发接口。后面简称ConcurrentHashMap为CHMap。不做特殊说明,所有jdk源代码都是基于1.7版本。
继承关系
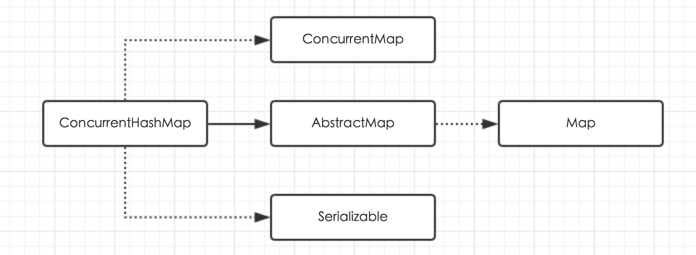
CHMap 继承自AbstractMap,具有普通Map的接口,同时实现了ConcurrentMap,提供额外的实用并发接口。
ConcurrentMap 含有的接口:

共提供了4个保证原子性的方法:
V putIfAbsent(K key, V value);
/**
* 等价于将下面的代码块作为原子操作
* if (!map.containsKey(key))
* return map.put(key, value);
* else
* return map.get(key);
*/
boolean remove(Object key, Object value);
/* This is equivalent to
* <pre>
* if (map.containsKey(key) && map.get(key).equals(value)) {
* map.remove(key);
* return true;
* } else return false;</pre>
*/
boolean replace(K key, V oldValue, V newValue);
/* This is equivalent to
* <pre>
* if (map.containsKey(key) && map.get(key).equals(oldValue)) {
* map.put(key, newValue);
* return true;
* } else return false;</pre>
*/
V replace(K key, V value);
/* This is equivalent to
* <pre>
* if (map.containsKey(key)) {
* return map.put(key, value);
* } else return null;</pre>
*/
在多线程场景下,为了保持集合数据的一致性,便抽象出了上面的实用接口。
Map含有的接口:
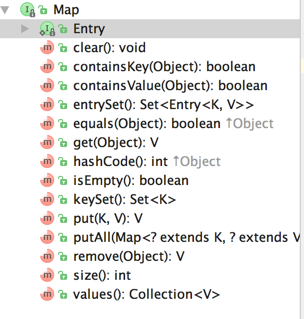
AbstractMap对Map的接口做了通用实现,所有的实现都是基于entrySet()这个方法,也就是子类只需要实现entrySet()即可。
实现原理
内部数据结构

CHMap 按照并发级别(默认为16,可以通过构造方法设定)设定Segment数组的长度,Segment继承自RenentrantLock 并实现了HashMap的功能,Segment可以被看做是优化版本的Hashtable,Segment内部方put、remove等操作需要对Segment对象加锁。
Segment内部使用HashEntry数组做存储结构,如上图所示,当遇到哈希碰撞时,通过开链表法保存数据。
公共方法时间复杂度分析
在了解内部存储结构后,public方法的时间复杂度便比较容易分析,源代码中多次采用了double check的技术,在加锁前通过两次验证modCount是否改变,来避免加锁,提高响应速
-
V get(Object key)
不加锁,通过哈希值定位到Segment,再次通过哈希值定位到HashEntry数组中的HashEntry,然后遍历链表。时间复杂度O(1)。
-
V put(K key, V value)需要对应的Segment需要加一把锁。
-
clear()需要对所有的Segment依次加锁。Segment之间不受影响。
-
boolean containsKey(Object key)不需要加锁。
-
boolean containsValue(Object value)
对modCount(修改次数)做double check,如果check成功,不加锁直接返回结果,否则对相应的Segment加锁。
-
boolean isEmpty()对modCount(修改次数)做double check,如果check成功且所有的Segment都空,则返回true,否则返回false。
-
V remove(Object key)
对Segment加锁后删除。
-
int size()对modCount(修改次数)做double check,如果check成功则返回所有的Segment Size 之和,否则要同时对所有Segment加锁,计算size,再同时释放锁。因此,高并发下此方法的效率最低。
总之,对Map的读取操作是不加锁的,时间复杂度等于O(1),对Map的添加、删除等操作,需要相应的Segment加锁,对Map的聚合方法(如何size()),double check失败后需要同时对所有Segment加锁,效率最低。
另外,如果业务的并发度很高,要记得在构造函数里提高并发级别。

This work is licensed under a CC A-S 4.0 International License.